Introduction to concepts
RDF stands for Resource Description Framework . It’s a way to represent information of all kinds. It’s now a W3C specification and since 1995 people are working on RDF and all sub subjects related to information representation for automatic system. It can be concidered as the « Grand Father » of graph storage.
The idea is very simple, all informations can be represented by a triplet :
(subject, predicate, object)
Storing data in a fancy way is nice, but the goal is to retrive data after. This is where SPARQL enters. It’s basically a SQL-like way to query your dataset made of RDF triplets.
DBpedia is the RDF wikipedia. It’s an open datastore that tries to gather and offers in RDF format, all information that you can find in wikipedia or other knowledge service. It very interesting because it preformats concepts and makes it avaiaible for automatic processes or complex query across concepts.
I’ll not go deeper into the wide subject of how to do RDF and SPARQL. I’ll go now step by step to explain briefely what we are doing, and that you can resue it, but if you are interested about RDF in general, look in google or buy books.
Dataset
There is a lot of possibilities of thema for this subject. This let’s play, we will look about relationship of people around movies. It’s not very original (but more than FB social network) but everybody will understand and the methodology can be applied in almost everything else.
/!\ Unfortunately, Dbpedia.org has frequent issues with its website, which means frequent Time Out or « Maintenance Time ». That’s life, usualy takes 5 min to come back. Use it to take a break /!\
Let’s Query
Basics
RDF / SPARQL is like any database in the world, it’s just a data store where you can query data. The main idea is to describe a pattern that the RDF engine will try to fetch on the element on the datastore.
Let’s say I want to have the information about Leonardo DiCaprio . His id in dbpedia is dbpedia.org/resource/Leonardo_DiCaprio .
To find the id of an entity, generally look for the entity page in wikipedia english and try http://dbpedia/resource/{wikipedia_Page_Id} . It works for most of the case. Note that if you put the id in the browser, it’s actually a « representation » of the id (notice that url changed to http://dbpedia/page/) . The page show us actually all entities associated to the current resource.
Let’s start with a simple query, go to http://dbpedia.org/sparql and query :
select *
where
{
<http://dbpedia.org/resource/Leonardo_DiCaprio> ?predicate ?object.
}
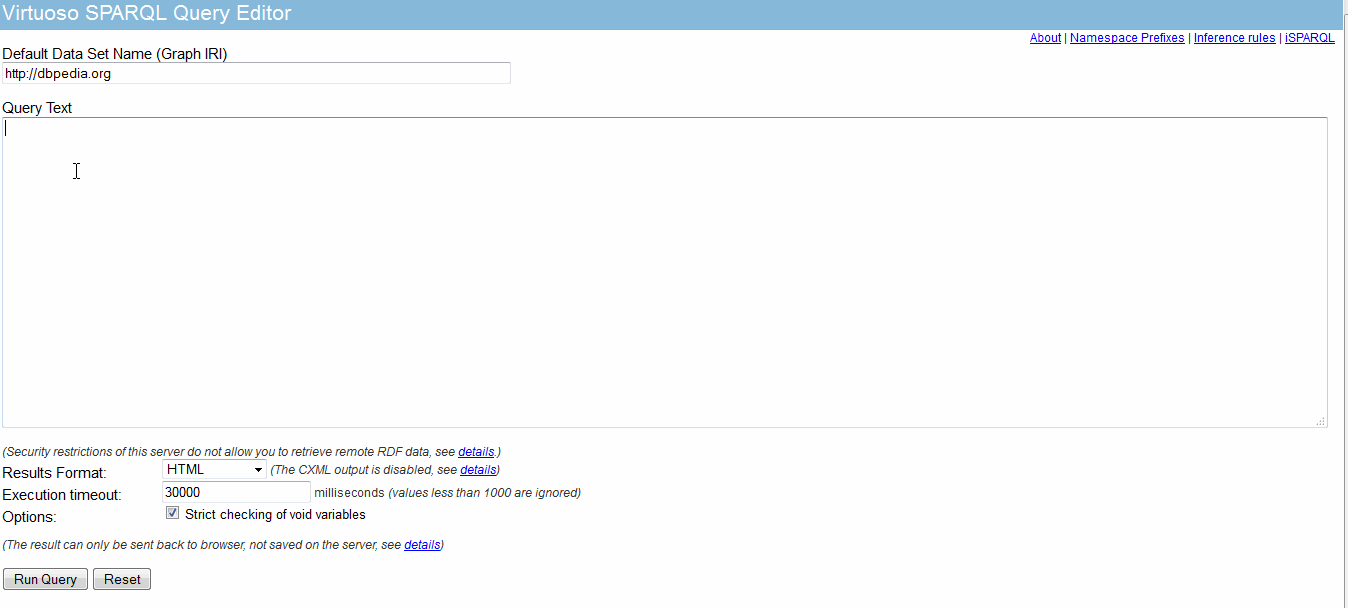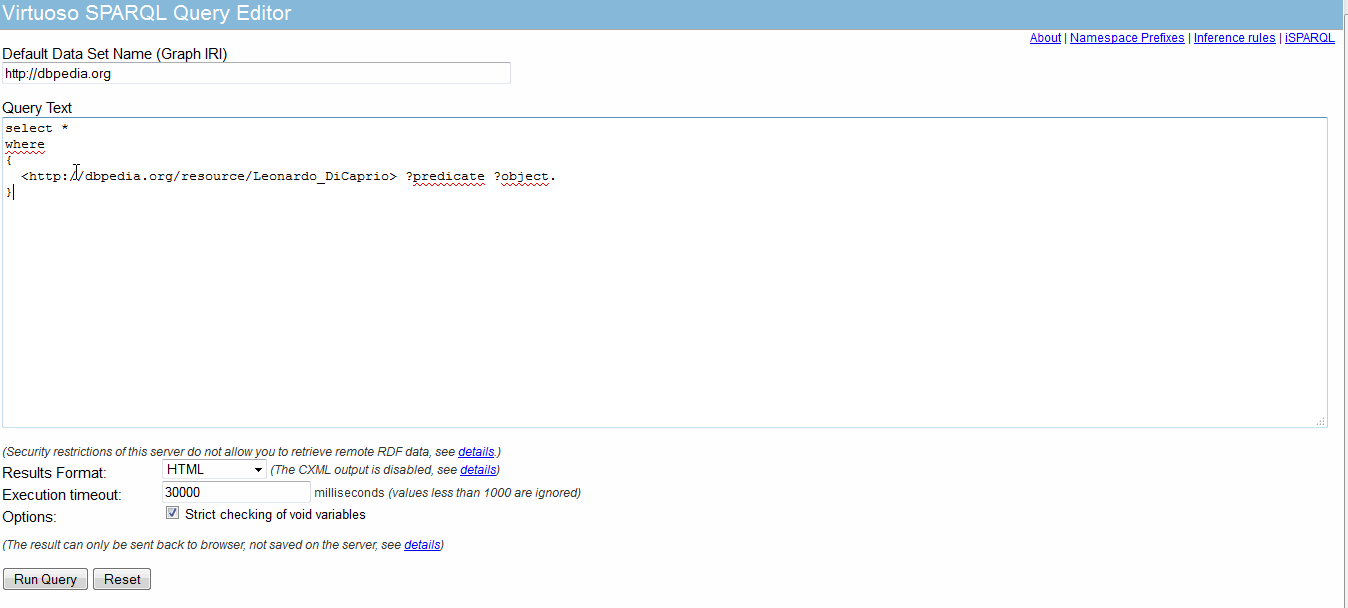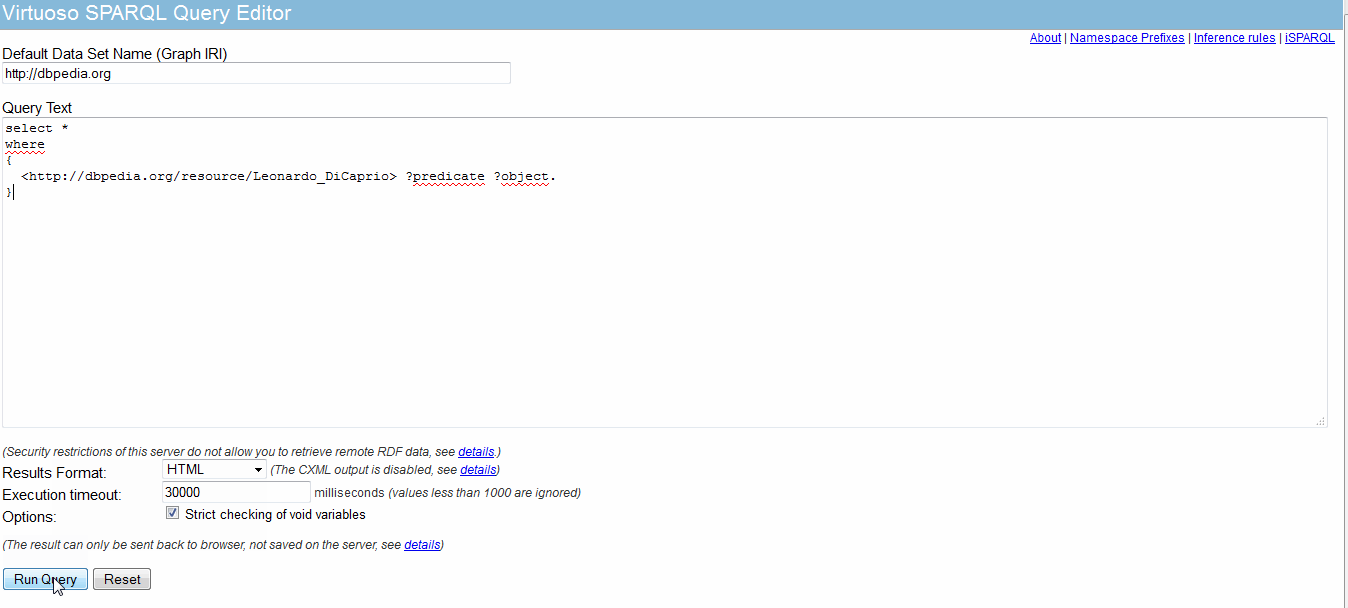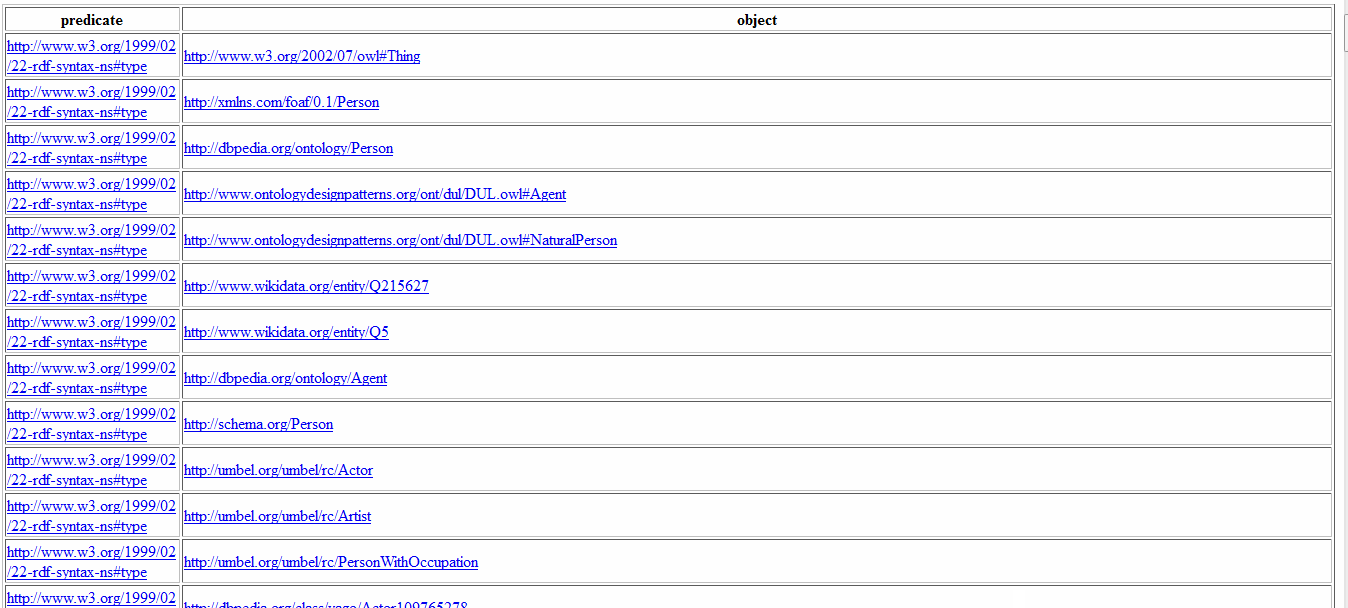
You shoud be able to return all (predicate, object) associated to Leonardo.
If we want particular information, like birthPlace, we just have to specify the the correct predicate :
select *
where
{
<http://dbpedia.org/resource/Leonardo_DiCaprio> <http://dbpedia.org/property/birthPlace> ?birthPlace.
}
And if we want actually all relations where Leonardo DiCaprio is the object, we just have to modify the first query like this:
select *
where
{
?subject ?predicate <http://dbpedia.org/resource/Leonardo_DiCaprio>.
}
More relations
Let’s go more advanced. We want the movies where DiCaprio is invovled:
select distinct *
where
{
?movie a <http://dbpedia.org/ontology/Film>.
?movie ?link <http://dbpedia.org/resource/Leonardo_DiCaprio>.
}
Let’s go step by step:
- ?movie a <http://dbpedia.org/ontology/Film> : Get all subject which is a <http://dbpedia.org/ontology/Film>. The ‘a’ is actally a SPARQL special word for <rdf:type>. So it’s exactly equal to ?movie <rdf:type> <http://dbpedia.org/ontology/Film>
- ?movie ?link <http://dbpedia.org/resource/Leonadro_DiCaprio>: In the result, ?movie must also have a ?link to Leonardo.
So the result is not only Movies where Leonardo DiCaprio played, but all movies where he has an involvement (actor, narrator, producer etc…) .

We can go deeper :
select distinct ?movie,?actor
where
{
?movie a <http://dbpedia.org/ontology/Film>.
?movie ?rel1 <http://dbpedia.org/resource/Leonardo_DiCaprio>.
?movie ?rel2 ?actor.
?actor a <http://dbpedia.org/ontology/Person>.
}
There it is ! We have a list of all movies where Leonardo DiCaprio was invovled and all people that were also invovled in theses movies.
Quick explanation on the last 2 lines:
- ?movie ?rel2 ?person. : Find all relation where ?movie is subject and ?actor is object.
- ?person a <http://dbpedia.org/ontology/Person> : Variable ?person must be a <rdf:type> <http://dbpedia.org/ontology/Person>. It basically exclude all related entities related to ?movie that are not relevent here like Cities, Award etc…
That’s it for querying data. I really briefely introduced RDF and SPARQL and I invite you to look closer on it if you are interested.
Let’s Graph
What we want to see now is the garph resulting the last query we’ve performed about Leonardo.
You always can write a script that use SPARQL api from dbpedia to convert the result into a CSV file. But Gephi has a plugin that can integrate directly SPARQL query into graph.
First, we need to install Semantic web import. You can find and install this plugins in the Tools -> Plugins part of you gephi.
When installed, go to the Semantic Web Import tab.
In Drivers tab, put http://dbpedia.org/sparql (AND PRESS !>ENTER<!).
Go to Query tab, remove the dummy query and put this one:
CONSTRUCT{
?person <http://gephi.org/type> "person".
?movie <http://gephi.org/type> "movie".
?movie <http://toto/link> ?person .
}
WHERE
{
?movie a <http://dbpedia.org/ontology/Film>.
?movie ?rel1 <http://dbpedia.org/resource/Leonardo_DiCaprio>.
?movie ?rel2 ?person.
?person a <http://dbpedia.org/ontology/Person>.
}
Go back to the Graph preview and you should see nodes.
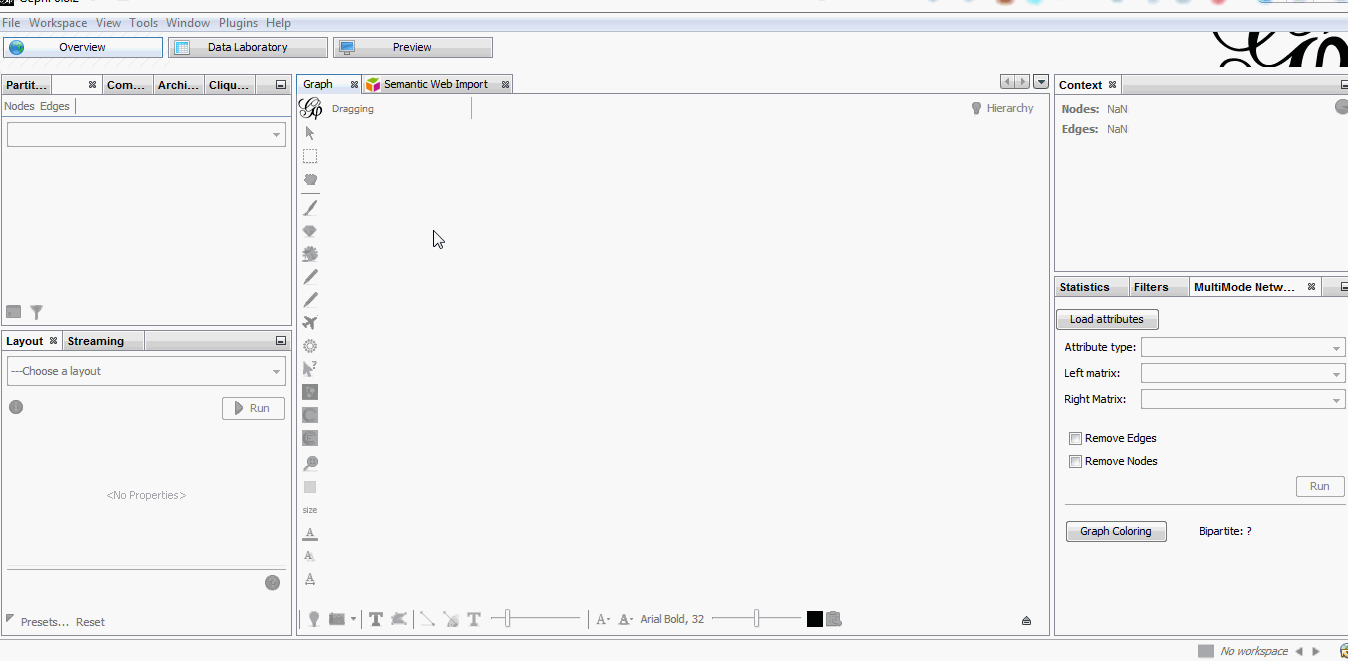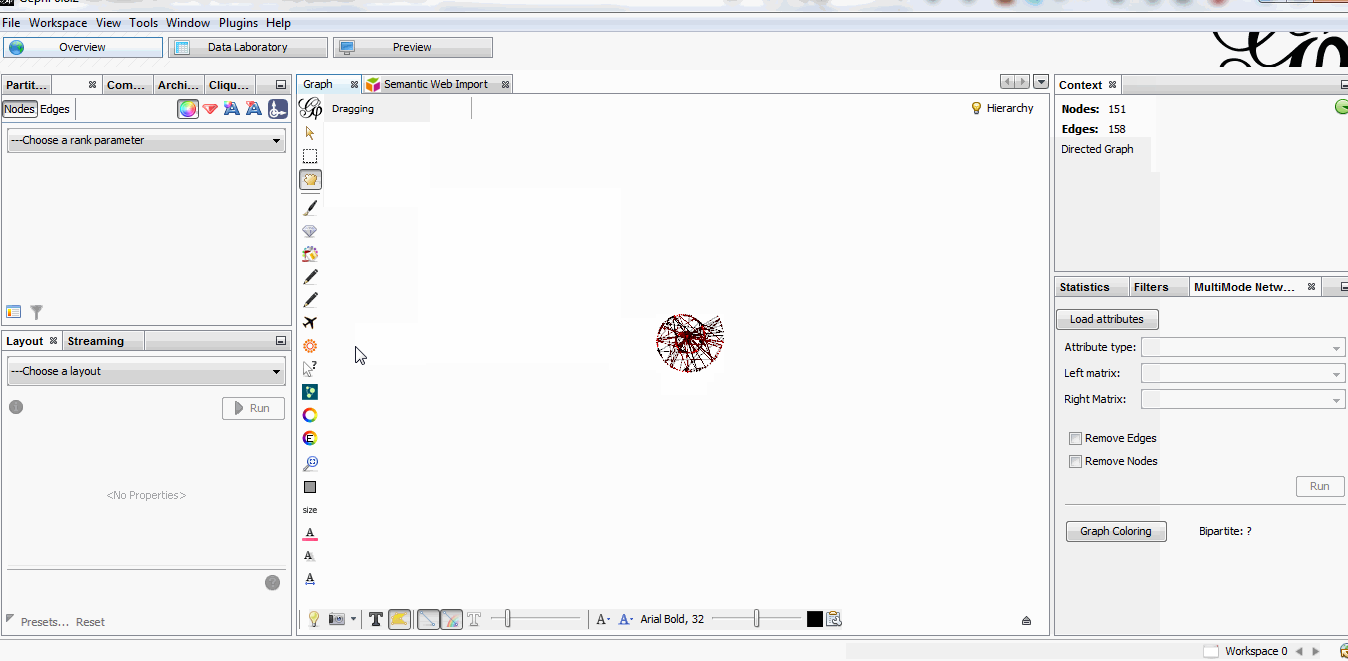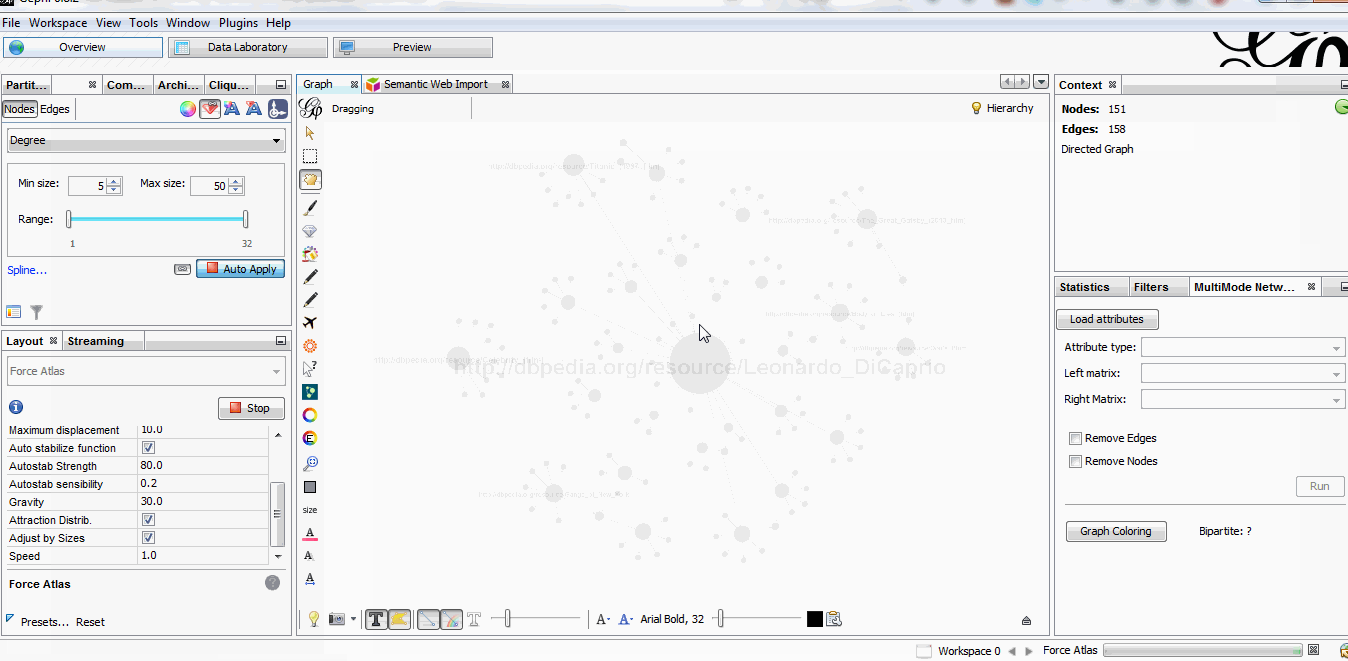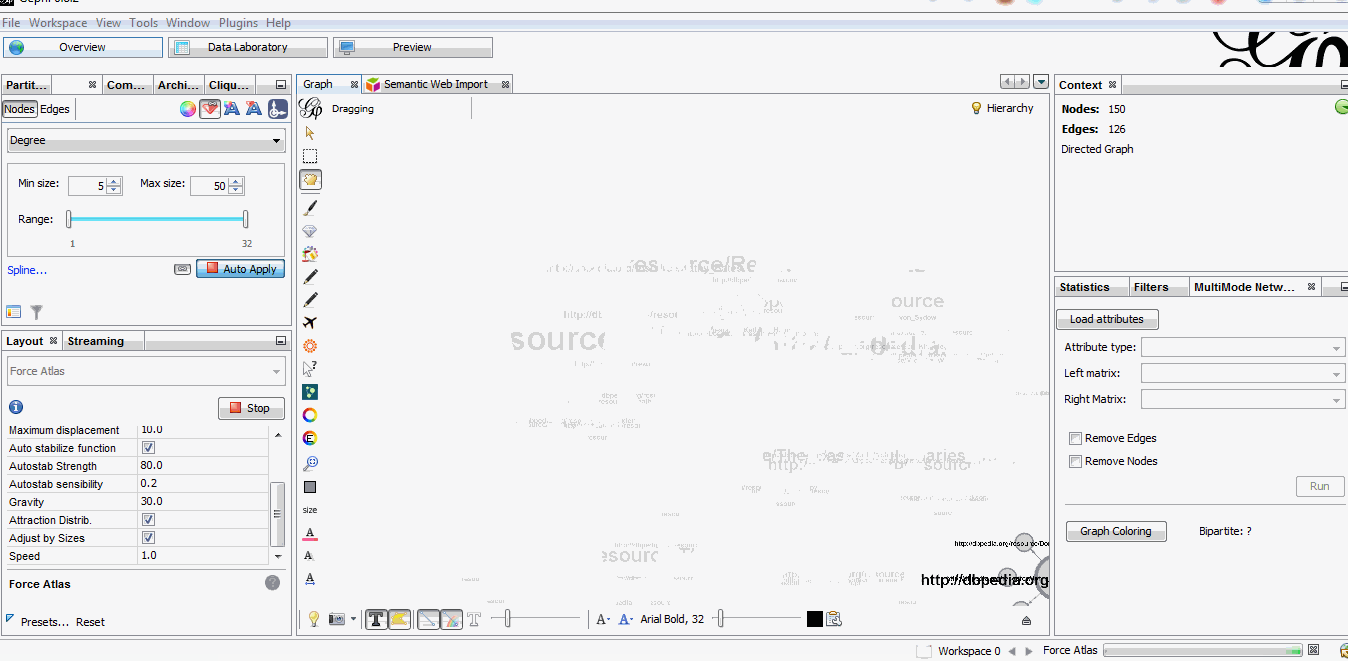
How does it works ?
You might have noticed that there is a strange block CONSTRUCT . That’s actually a feature of SPARQL allowing you to create a new graph from a query. And that’s where the magic works, the plugin execute the query, get a graph in return, and draw it in gephi.
What is the syntax for this CONSTRUCT block :
- ?a <http://gephi.org/{nodeProperty}> ?b : Will create the node ?a with the property nodeProperty equals to ?b.
- ?a (<what_You_Want> or ?c) ?b : will create a link between ?a and ?b with label <what_You_Want>
The result in our case is actually a bi-modal graph with Movies and Persons. I advise you to read the Let’s play about multimodal graph if you want advanced analysis of this kind of network.
What is interesting with this method is the way to query the data, and the fact that it’s easily extendable to other subjects just by changing few things in the query. We can think about Music Band and Player relationship, the traditionnal Persons to Companies, or more original, all the common places where your favorites movies where shot, etc.. The limit is your imagination to graph.
On our example, you can run multiple time the same query and changing which person you want to « expand », it will automatically create the global network of all your research and maybe give you some insight which new movies to watch tonight 😉
But keep in mind that you are heavily dependent on Dbpedia data quality (or other RDF entrypoint), which can alterate a lot you research.
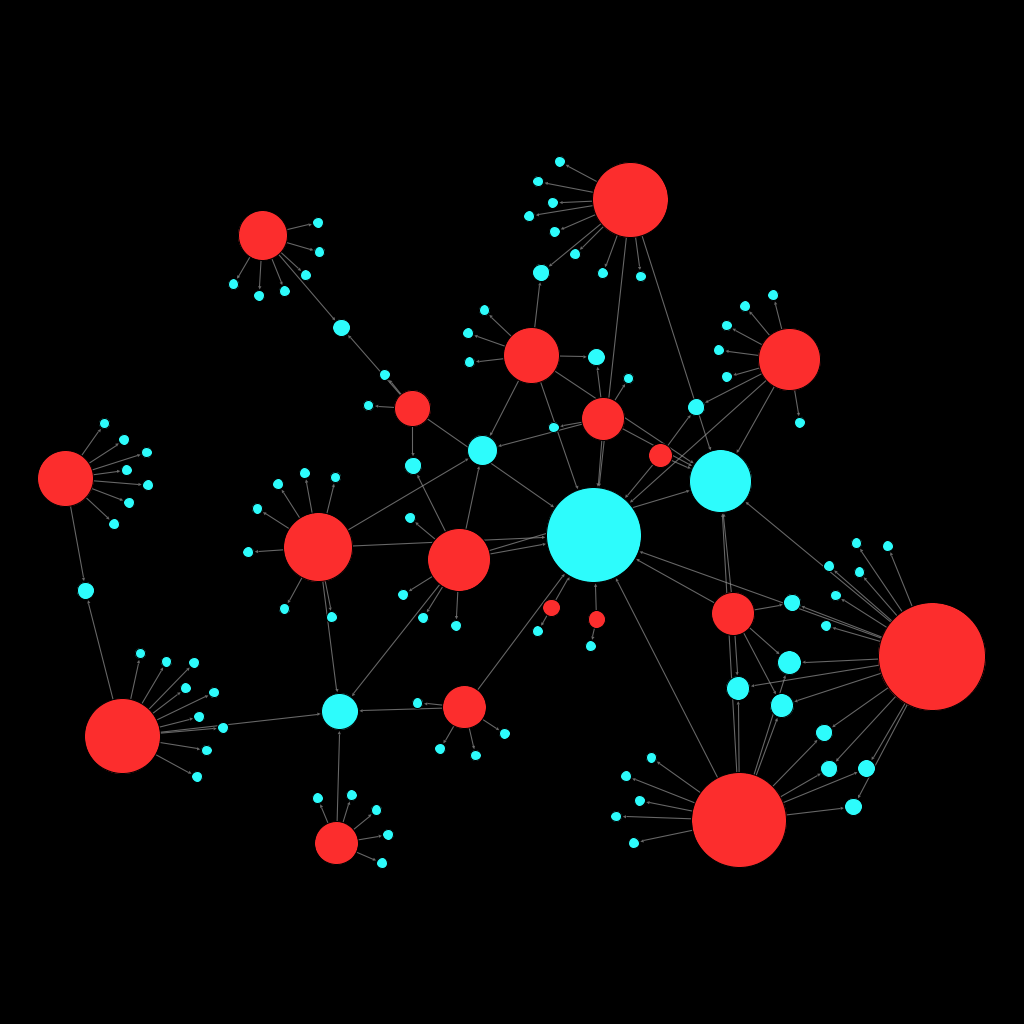
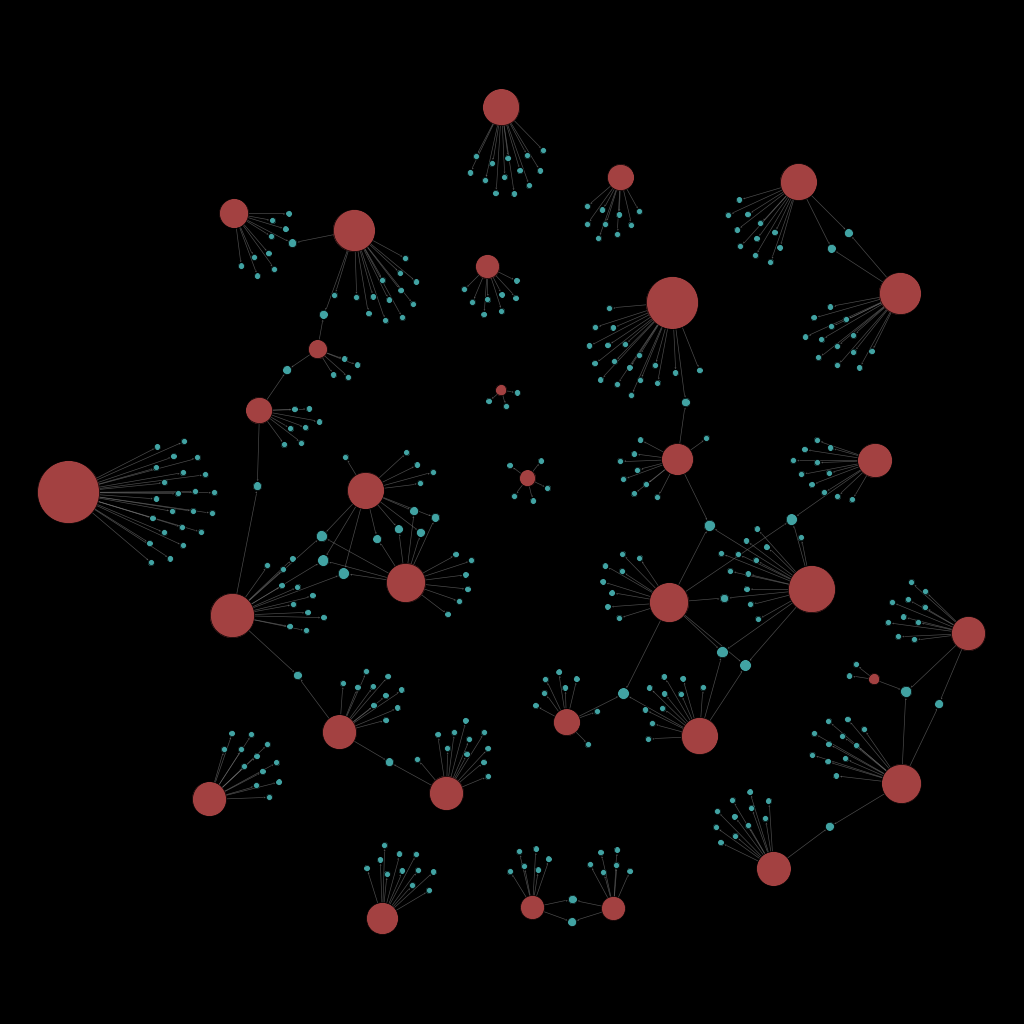
To finish, I let you with some random network from randomly selected people.
Leonardo DiCaprio (Actor)
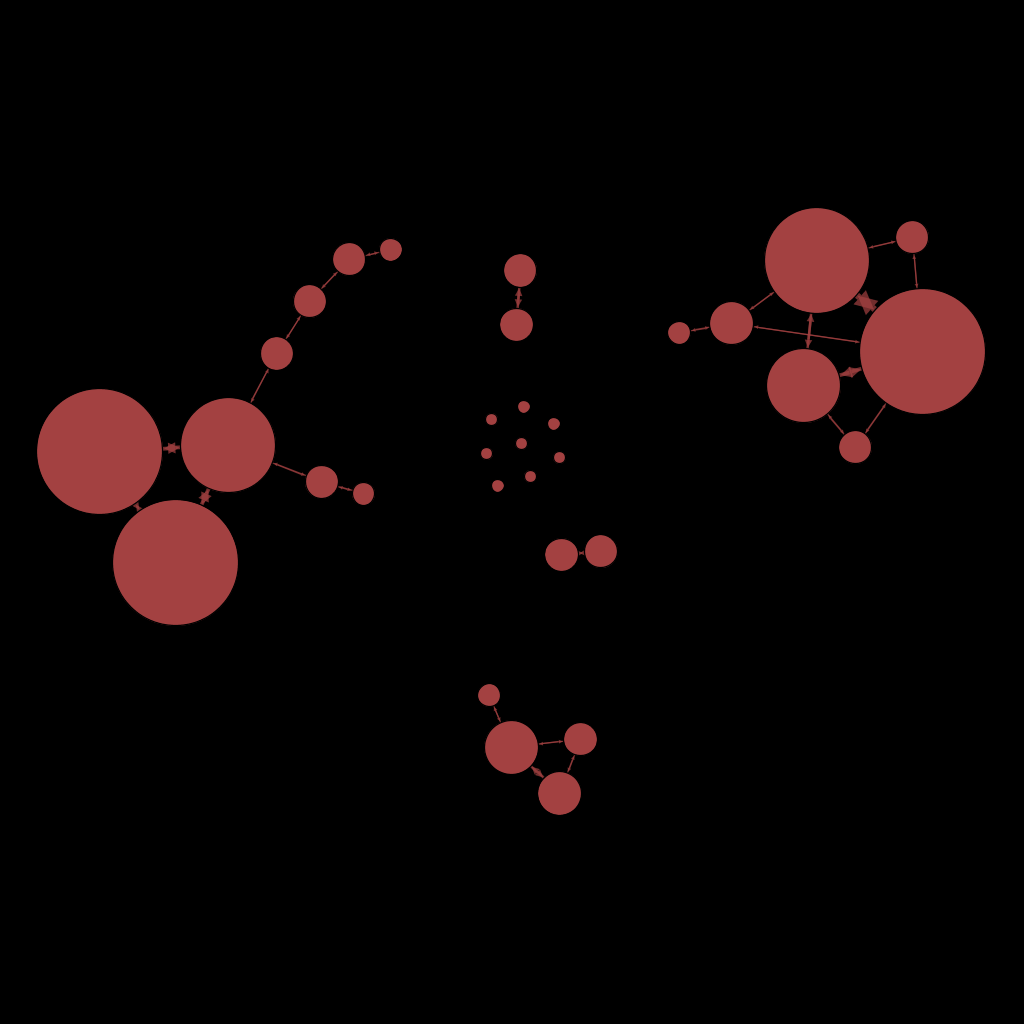

Werner Herzog (Director)
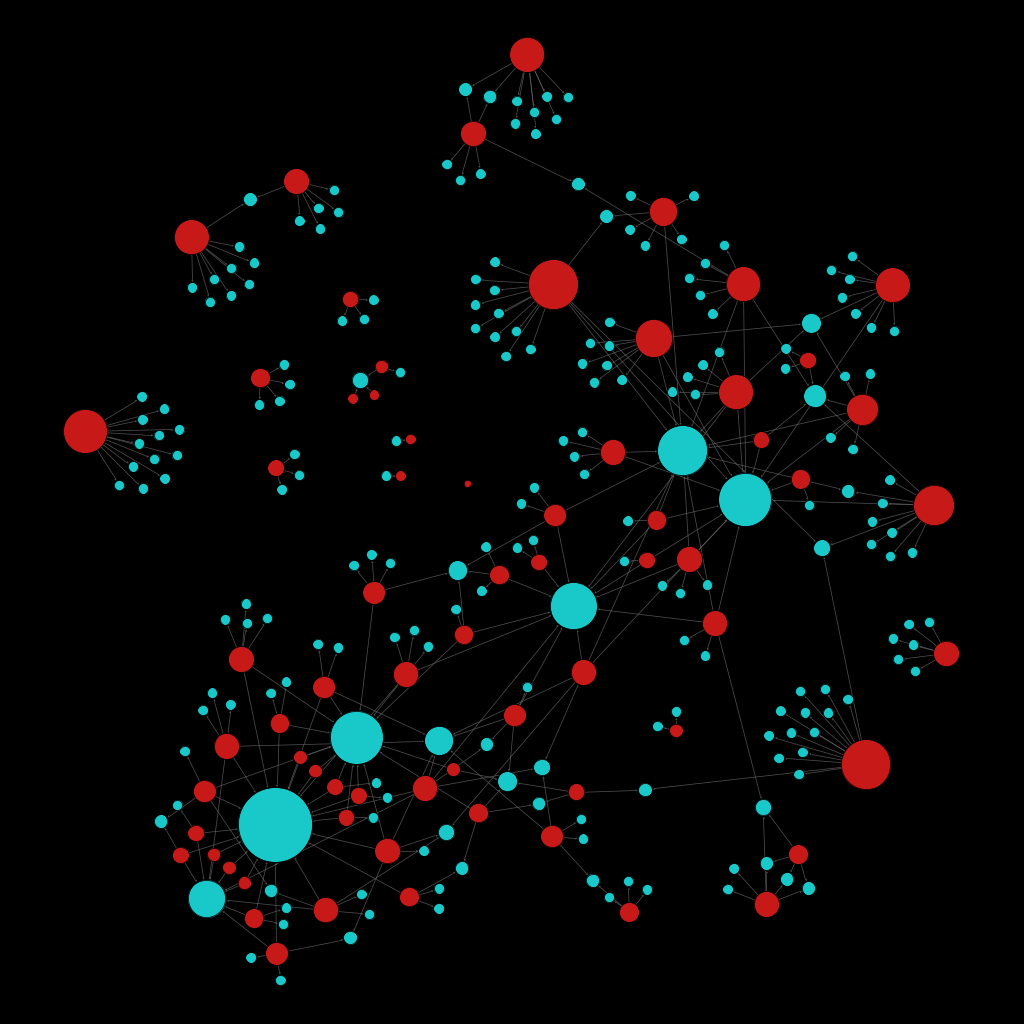
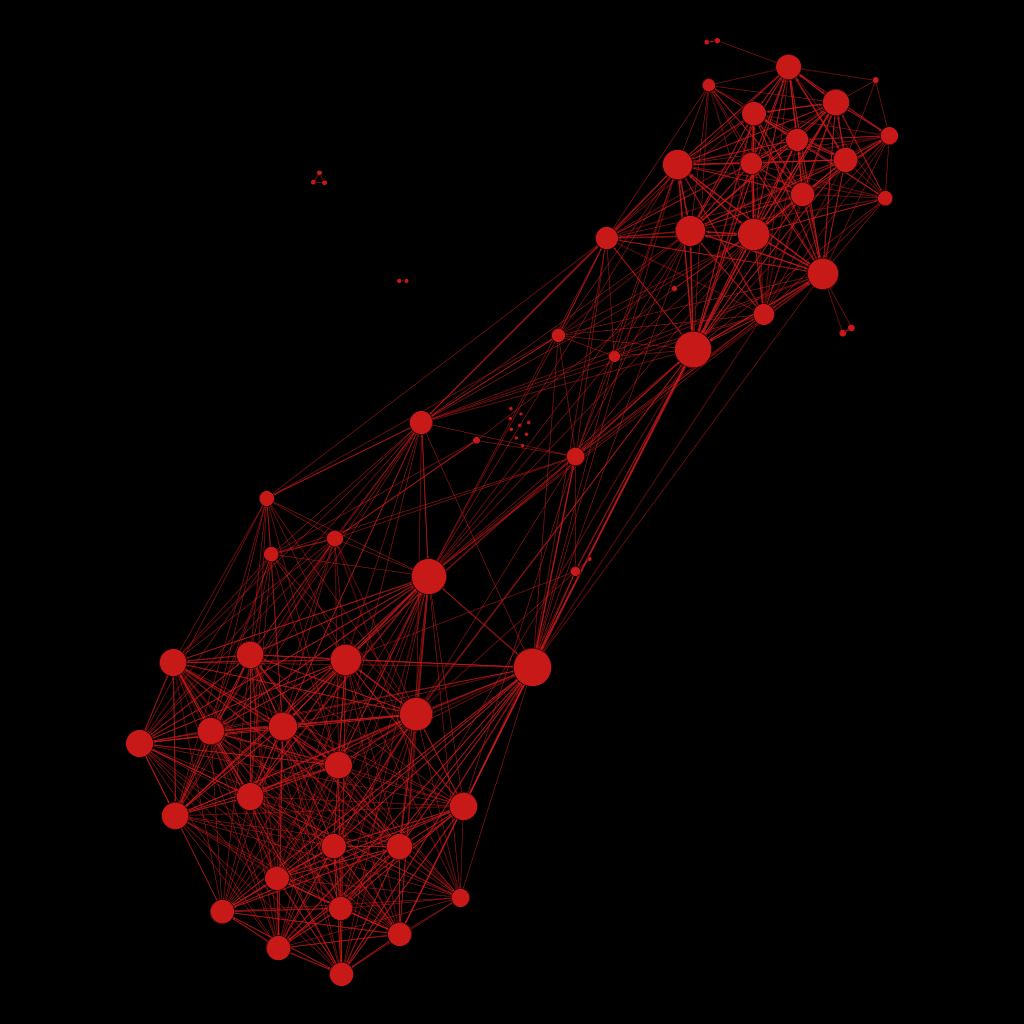

Eric Serra (Music Composer)